Motivation
As exponentially growth of data happening on everywhere of our daily life, and cheaper cost of computational resource, two areas of computer science become more prevalent:
Distributed computing with high-performance and fault-tolerance features play an important role nowadays. With the power of distributed computing, tasks with PetaByte data can be processed in several hours compared traditional single node computation, which typically have to spend several days and weeks to process. Apache Spark is currently the most shinning cluster computing engine in the Hadoop ecosystem, it is able to provide up to 100x faster than Hadoop MapReduce in memory.
Machine learning explores the study of construction of algorithm that can learn and make prediction on data. Such algorithms operate by building a model from example input data and make data-drive prediction. Machine learning make our life easier than ever in many ways, such as search engine, recommendation system, spam filter and risk analysis.
Both areas are super interesting for me when I explore and study them, and both of them exhibit great potential and value in their area. There are so many fun topics of each area I can learn and play. But how about create a cool project that combines some key features of both area, not only I can deeply learn knowledge of distributed computing and Machine learning algorithms, but also get some hands on experience of solving problem on distributed system with functional programming paradigm by Scala.
Twitter steaming sentiment analysis is an excellent choice based on my proposal. Every day around 500 million tweets are produced from all over the world, and around one percent of them are public available, that is 5 millions tweets. Apache Spark streaming is the best candidate to process such huge amount of data on distributed nodes. Naive Bayes classifier is one of the Machine learning algorithm to make sentiment prediction on each tweet.
Project description
This is a big data project about streaming sentiment analysis(positive and negative) based on Naive Bayes Classifier, which had been trained with data set of 1,6000,000, on 5 millions tweets everyday running on Apache Spark Streaming build on top of Spark Core Engine. User will see accumulated count of positive and negative sentiment in English for each location from all over the world in real time. All sentiment analysis results are published to Apache Kafka, and are subscribed by Scala Play server so web client can see the results via WebSocket connection.
Here is the Github Repo of Streaming Sentiment Analysis
Project Architecture
The whole system is comprised of three different modules, Kafka twitter streaming producer, sentiment analysis consumer, and Scala Play server consumer. Sentiment analysis consumer is made up of Apache Spark streaming and Naive Bayes Classifier model trained by using Apache Spark MLlib. Apache Kafka serves as the central data backbone to connecting all three different decoupled parts by publish-subscribe messaging style.
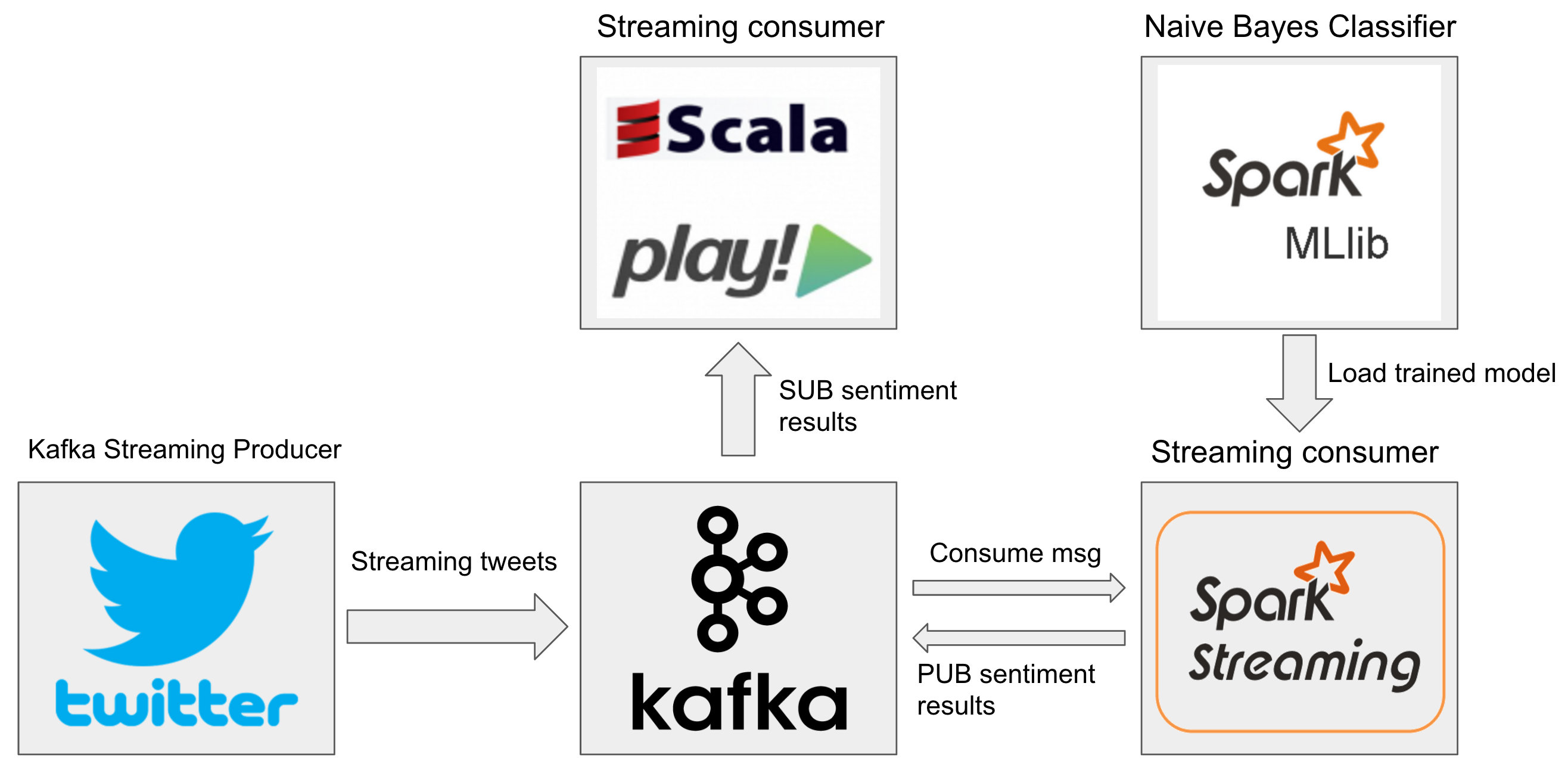
Data flow
Kafka twitter streaming producer publishes streaming tweets on the ‘tweets’ topic to the central Apache Kafka, and sentiment analysis consumer has subscribed that ‘tweets’ topic. The sentiment analysis consumer leverage Apache Spark Streaming to perform batch processing on incoming tweets and load trained Naive Bayes model to perform sentiment analysis. And then accumulated count of each positive sentiment and negative sentiment reduced by each location are published on topic ‘sentiment’ to central Kafka, and this ‘sentiment’ topic subscribed by Scala Play Server. The sentiment analysis results will be send to web clients through webSocket connections.
System Design
All different parts of modules, Kafka Twitter Streamming Producer, Apache Kafka, Apache Spark Streaming and Scala Play server are run docker locally.
Kafka Twitter Streaming Producer
It’s a Kafka producer used for publishing streaming tweets to central Apache Kafka on topic ‘tweets’ in real time from all over the world in English by using twitter4j library for twitter API
Apache Kafka
Apache Kafka is a high-performance distributed, partitioned, replicated publish-subscribe messaging system. Kafka cluster serve as the central data backbone for a large organization and highly valuable for enterprise infrastructures to process streaming data.
A stream of messages belonging to a particular category is called a topic. Data is stored in topics. Topics are split into partitions. Each partition is an ordered immutable sequence of message that is continually appended to—a commit log. And each partition is replicated across a configurable number of servers for fault tolerance. Each partition has one server which acts as the “leader” and zero or more servers which act as “followers”. The leader handles all read and write requests for the partition while the followers passively replicate the leader.
ZooKeeper is used for managing and coordinating Kafka broker in kafka cluster. If the leader fails, zookeeper will choose one of the followers as the new leader.
This project was configured as one kafka broker and one zookeeper. It mainly used as PUB/SUB message queue for raw streaming tweets and results of sentiment analysis of tweets. It connects decoupled modules of the entire system, so each module work independently without realize the existence of other. It maintained two topics in this project, ‘tweets’ and ‘sentiment’, one for raw steaming tweets and the other for results of sentiment analysis of each location.
Naive Bayes Classifier Model
Machine learning is the study and construction of algorithm that can learn from data and make data-driven prediction. Depending on learning ‘feedback’ available to learning system, Machine learning tasks are classified into three categories:
- Supervised learning
- Unsupervised learning
- Reinforcement learning
Machine learning algorithms are break down in several categories based on similarity
- Regression Algorithms
- Bayesian Algorithms
- Clustering Algorithms
- Artificial Neural Network Algorithms
- Deep Learning Algorithms
- and more …
Bayes’ theorem describes the probability of an event, based on conditions that might be related to the event:
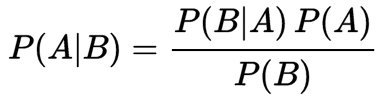
Naive Bayes is not a single algorithm, but a family of probabilistic classifiers of supervised learning algorithms based on applying Bayes’ theorem with the “naive” assumption of independence between every pair of features solving classification problem. Naive Bayes algorithm has widely use case in our daily life, such as classify spam email, zombie account and document classification.
Based on assumptions on distributions of features from training set, Naive Bayes classifier, for discrete features like the ones encountered in document classification (include spam filtering), multinomial and Bernoulli distributions are popular. Apache Spark MLlib supports Multinomial Naive Bayes and Bernoulli Naive Bayes. These models are typically used for document classification. The third one is Gaussian naive Bayes dealing with continuous data that has Gaussian distribution. Multinomial Naive bayesas is the default in Spark MLlib and used in this project.
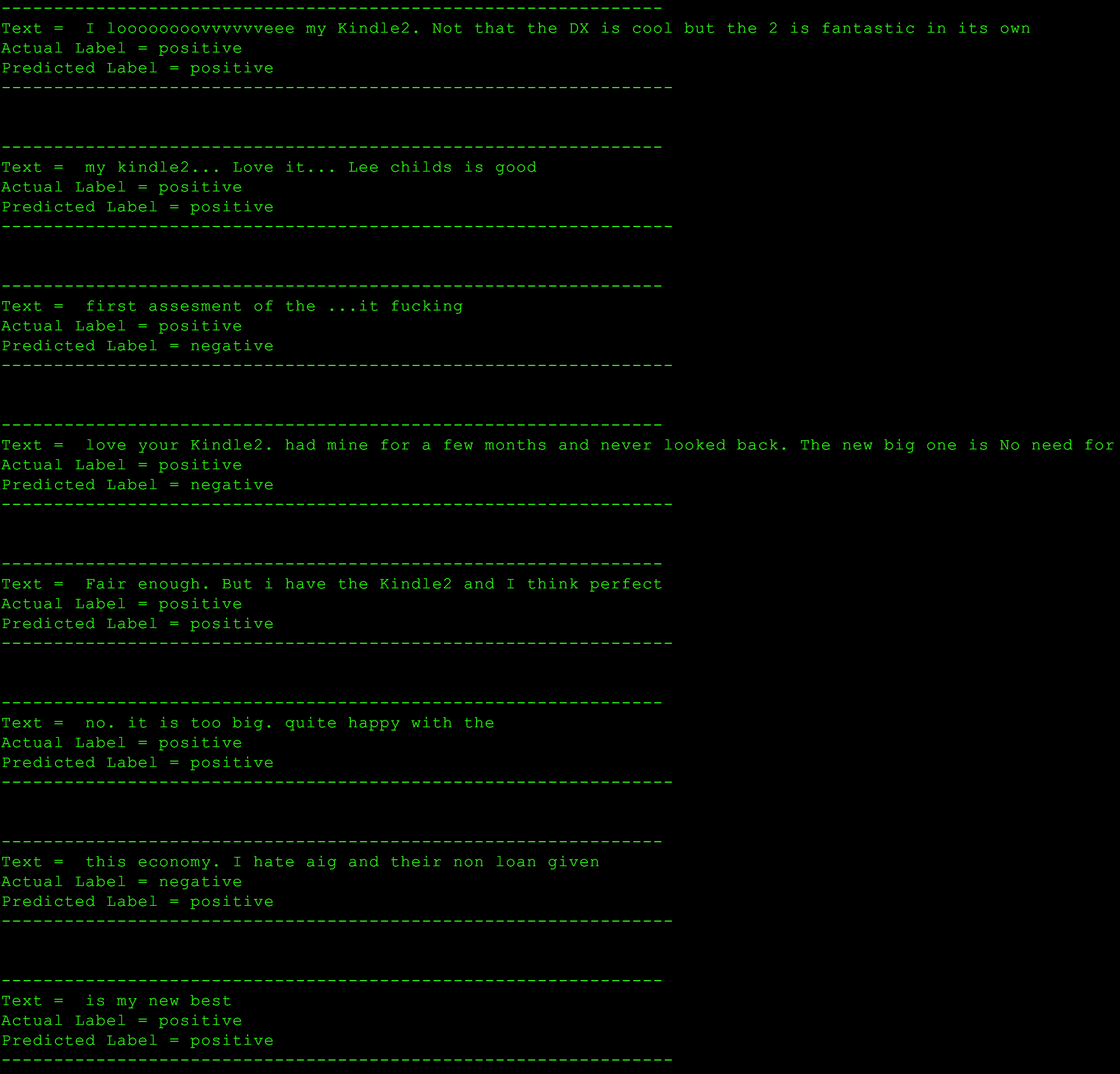
The training data set and test data set are from sentiment140, which contains 1.6 million training data set of tweets marked as positive and negative emotion for each tweet. The spark naive bayes model was trained by these amount of data with removal of stop words to improve accuracy. The accuracy of trained model is around 78% by running test data set.
(stop words are most common words in a language, like is, a, the, an, which, such and on, they don’t contribute much information to processing of natural language)
Apache Spark Streaming
Apache Spark v1.6 was used to build this system
Spark Core
Apache Spark is a fast and general-purpose distributed cluster computing framework. Spark core is the foundation of overall project. It supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming.
Spark’s primary data abstraction is a distributed collection of items called a Resilient Distributed Dataset (RDD). RDD represents an immutable, partitioned collection of elements that can be operated on in parallel with fault-tolerance.
RDD has several traits:
- Resilient, i.e. fault-tolerant with the help of RDD lineage graph and so able to recompute missing or damaged partitions due to node failures. Compared to Hadoop MapReduce, which persists data to disk after map or reduce action, achieve fault-tolerant by replicating same block of data three times on different nodes. This one of reason Spark faster than Hadoop MapReduce.
- Immutable or Read-Only, i.e. it does not change once created and can only be transformed using transformations to new RDDs.
- Lazy evaluated, i.e. the data inside RDD is not available or transformed until an action is executed that triggers the execution.
- Partitioned, i.e. the data inside a RDD is partitioned (split into partitions) and then distributed across nodes in a cluster. Partitions are the units of parallelism
The motivation of creating RDD was to solve two type of application that current computing framework handles inefficiently:
- iterative algorithms, i.e. machine learning and graph computation.
- interactive data mining tools , i.e. ad-hoc queries on the same dataset.
The goal is to reuse intermediate in-memory results across multiple data-intensive workloads with no need for copying large amounts of data over the network.
Spark Streaming
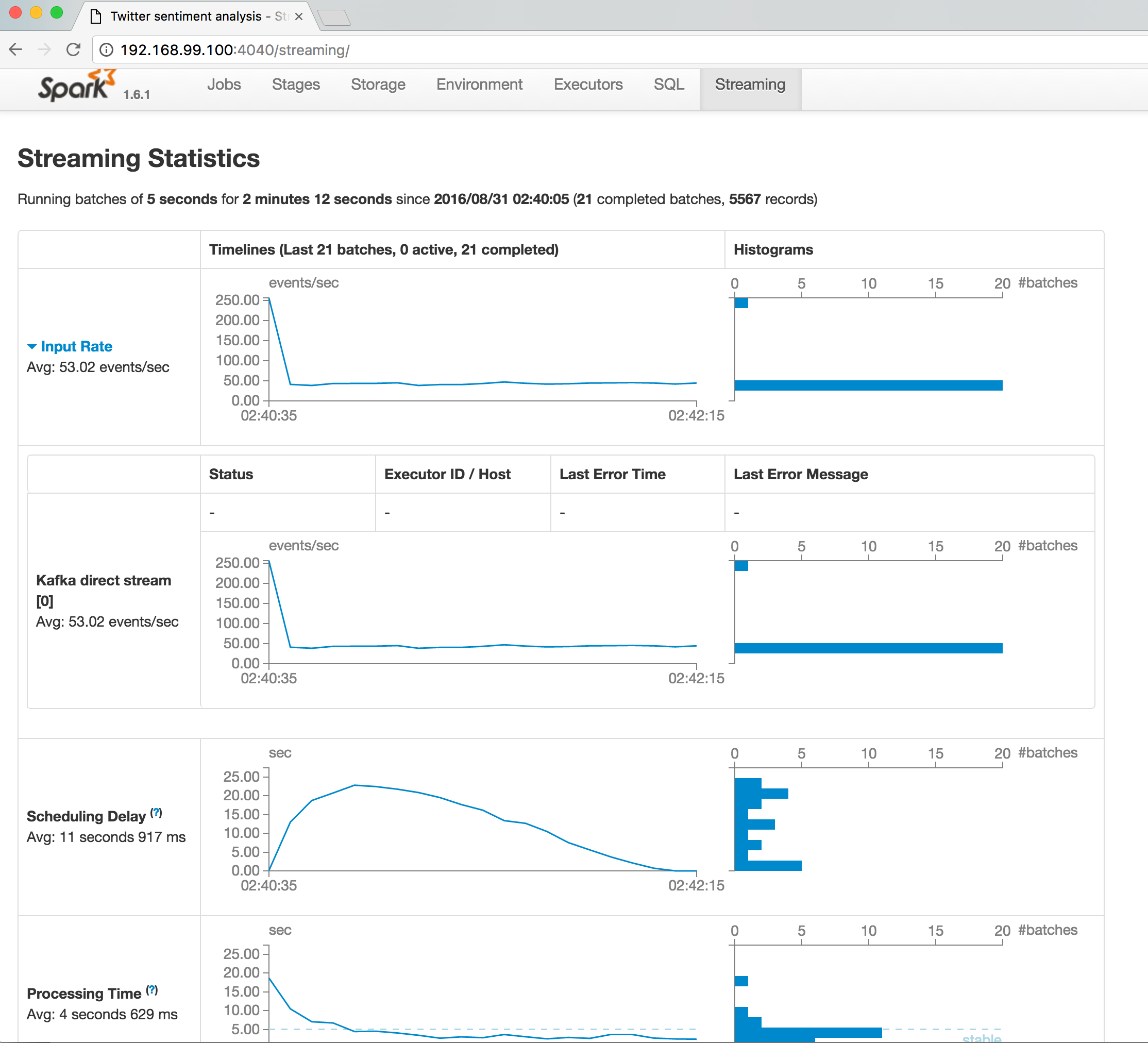
Spark streaming leverages spark core to perform streaming analysis. Discretized Stream or DStream is the basic abstraction provided by Spark Streaming. It represents a continuous stream of data, either the input data stream received from source, or the processed data stream generated by transforming the input stream. Internally, a DStream is represented by a continuous series of RDDs.Each RDD in a DStream contains data from a certain interval, as shown in the following figure.

Any operation applied on a DStream translates to operations on the underlying RDDs.
The major part of the project is to perform serial of transformations on input of raw tweets streaming while apply trained Naive Bayes model on each of them, then publish results to Kafka. The transformation on DStreams can be grouped into either stateless or stateful.
Stateless transformations are simple RDD transformation being applied on every batch, that is, every RDD in a DStream, such map(), flatMap(), filter(), reducedByKey() and so on. Stateless transformations was used to filter emotion icon, link and non alphanumeric characters in each tweet, map each tweet to tuple format of (city, positive/negative sentiment)
Statefull transformation are operations on DStream that track data across time, that is, some data from previous batches is used to generate the results for a new batch. updateStateByKey() is used to accumulate total number of positive or negative count of sentiment results for each location from beginning of running the project.
Code example of Spark Streaming transformations and applying of Naive bayes model
def start = {
val tweetsStreaming = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder] (sc, kafkaParams, topic)
val rawTweets = tweetsStreaming.map(_._2)
rawTweets.window(Seconds(5), Seconds(5)).saveAsTextFiles(s"/rawResults/tweet")
val rawLocationText= rawTweets.map(TwitterObjectFactory.createStatus).map(CustomizeTweet(_))
rawLocationText.window(Seconds(5), Seconds(5)).saveAsTextFiles(s"/rawLocationText/ct")
//filtering tuple, sanitise location
val cityText = rawLocationText.filter(x => TweetUtils.sanitiseLocation(x._1)).map{ case (k,v) => (k.split(",")(0), v)} //location from tweet, "city, country"
cityText.window(Seconds(5), Seconds(5)).saveAsTextFiles(s"/cityText/ct")
//filtering tuple, sanitise text
val cleanCityText = cityText.map{ case (k, v) => (k, TweetUtils.filterOnlyWords(v))}.filter(x => TweetUtils.filterEmptyString(x._2))
cleanCityText.window(Seconds(5), Seconds(5)).saveAsTextFiles(s"/cleanCityText/ct")
//loading Naive Bayes model
println("Loading the Naive Bayes model...")
val model = NaiveBayesModel.load(sc.sparkContext, "src/main/model/")
println("Start predicting...")
/**
* analyze sentiment of each tweet
* data format: (city, (msg, predicted value))
*/
val cityTextPredictedValue= cleanCityText.map(x => (x._1, (x._2, model.predict(TrainingUtils.featureVectorization(x._2)))))
cityTextPredictedValue.window(Seconds(5), Seconds(5)).saveAsTextFiles(s"/cityTextPredictedValue/ct") // save this data structure for reference and debugging
/**
* predicted sentiment value for each city
* data format: (city, 4.0) or (city, 1.0)
*/
val cityPredictedValue = cleanCityText.map(x => (x._1, model.predict(TrainingUtils.featureVectorization(x._2)).toString))
/**
* group predicted sentiment values for each city
* data format: (city, 4.0 1.0 4.0)
*/
val reducedCityPredictedValue = cityPredictedValue.reduceByKey((x, y) => x + " " + y)
reducedCityPredictedValue.window(Seconds(5), Seconds(5)).saveAsTextFiles(s"/reducedCityPredictedValue/ct")
/**
* classify positive sentiment value and count them
* data format: (city, num of positive value) e.g. (city, 2) ...
*/
val numPositivePredictedValue = reducedCityPredictedValue.map(x => (x._1, x._2.split(" ").filter( x => x.toDouble == 4.0).mkString(" "))) // filtering negative value
.map{ case (k:String, v:String) => if(!v.isEmpty) (k, v.split(" ").length) else (k, 0)} //counting the number of positive predicted value
numPositivePredictedValue.window(Seconds(5), Seconds(5)).saveAsTextFiles(s"/numPositivePredictedValue/ct")
//accumulate counting of positive sentiment tweet per city, accumulate from beginning of the app
val totalPositiveTweetPerCity = numPositivePredictedValue.updateStateByKey(TweetUtils.accumulateSentimentCount _ )
totalPositiveTweetPerCity.window(Seconds(5), Seconds(5)).saveAsTextFiles(s"/totalPositiveTweetPerCity/ct")
/**
* classify negative sentiment value and count them
* data format: (city, num of negative value) e.g. (city, 2) ...
*/
val numNegativePredictedValue = reducedCityPredictedValue.map(x => (x._1, x._2.split(" ").filter( x => x.toDouble == 0.0).mkString(" "))) //filtering positive value
.map{ case (k:String, v:String) => if(!v.isEmpty) (k, v.split(" ").length) else (k, 0)} //counting the number of positive predicted value
numNegativePredictedValue.window(Seconds(5), Seconds(5)).saveAsTextFiles(s"/numNegativePredictedValue/ct")
//accumulate counting of positive sentiment tweet per city, accumulate from beginning of the app
val totalNegativeTweetPerCity = numNegativePredictedValue.updateStateByKey(TweetUtils.accumulateSentimentCount _ )
totalNegativeTweetPerCity.window(Seconds(5), Seconds(5)).saveAsTextFiles(s"/totalNegativeTweetPerCity/ct")
/**
* join positive and negative count of sentiment value for each city
* data format: (city, (count of positive, count of negative))
*/
val joinPositiveNegativeCountPerCity = totalPositiveTweetPerCity.join(totalNegativeTweetPerCity)
joinPositiveNegativeCountPerCity.print()
joinPositiveNegativeCountPerCity.window(Seconds(5), Seconds(5)).saveAsTextFiles(s"/joinPositiveNegativeCountPerCity/ct")
/**
* publish sentiment count of each city back to Kafka with different kafka topic
*/
joinPositiveNegativeCountPerCity.foreachRDD{
rdd => rdd.foreachPartition {
partitionOfRecords => {
val producer = new Producer[String, String](new ProducerConfig(KafkaConfig.kafkaProps))
partitionOfRecords.foreach {
message => producer.send(new KeyedMessage[String, String](KafkaConfig.KAFKA_SENTIMENT_TOPIC, message.toString()))
}
producer.close()
}
}
}
// Start the streaming computation
println("Spark Streaming begin...")
sc.start()
sc.awaitTermination()
}
}
Scala Play server
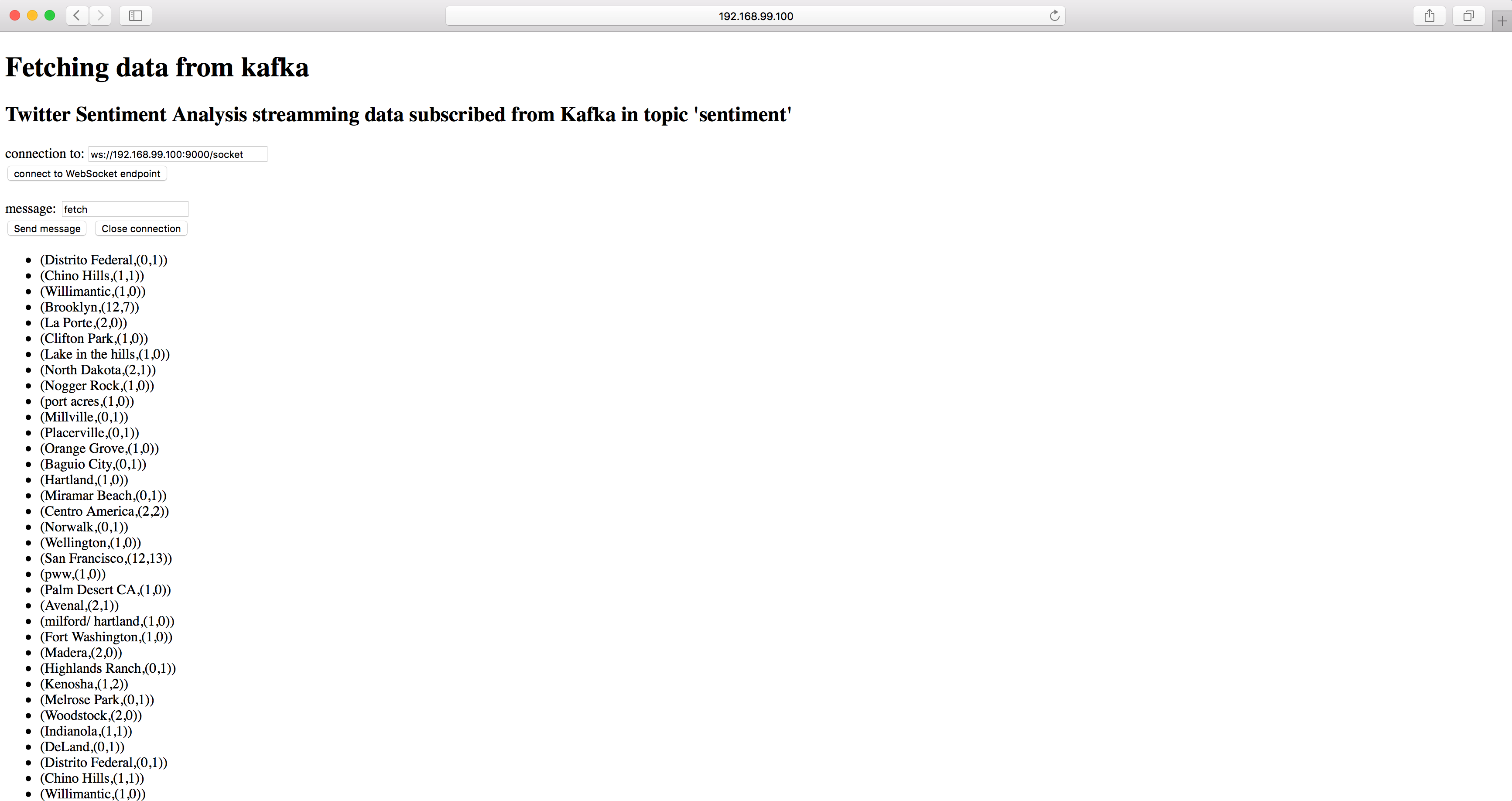
Play framework is build on Akka, which is a toolkit and runtime for building highly concurrent, distributed, and resilient message-driven applications on the JVM. Akka emphasizes actor-based concurrency, with inspiration drawn from Erlang. The Play server subscribed topic ‘sentiment’ from Kafka and continuously consumes streaming sentiment results from Kafka, and send them to web client through WebSocket connection.
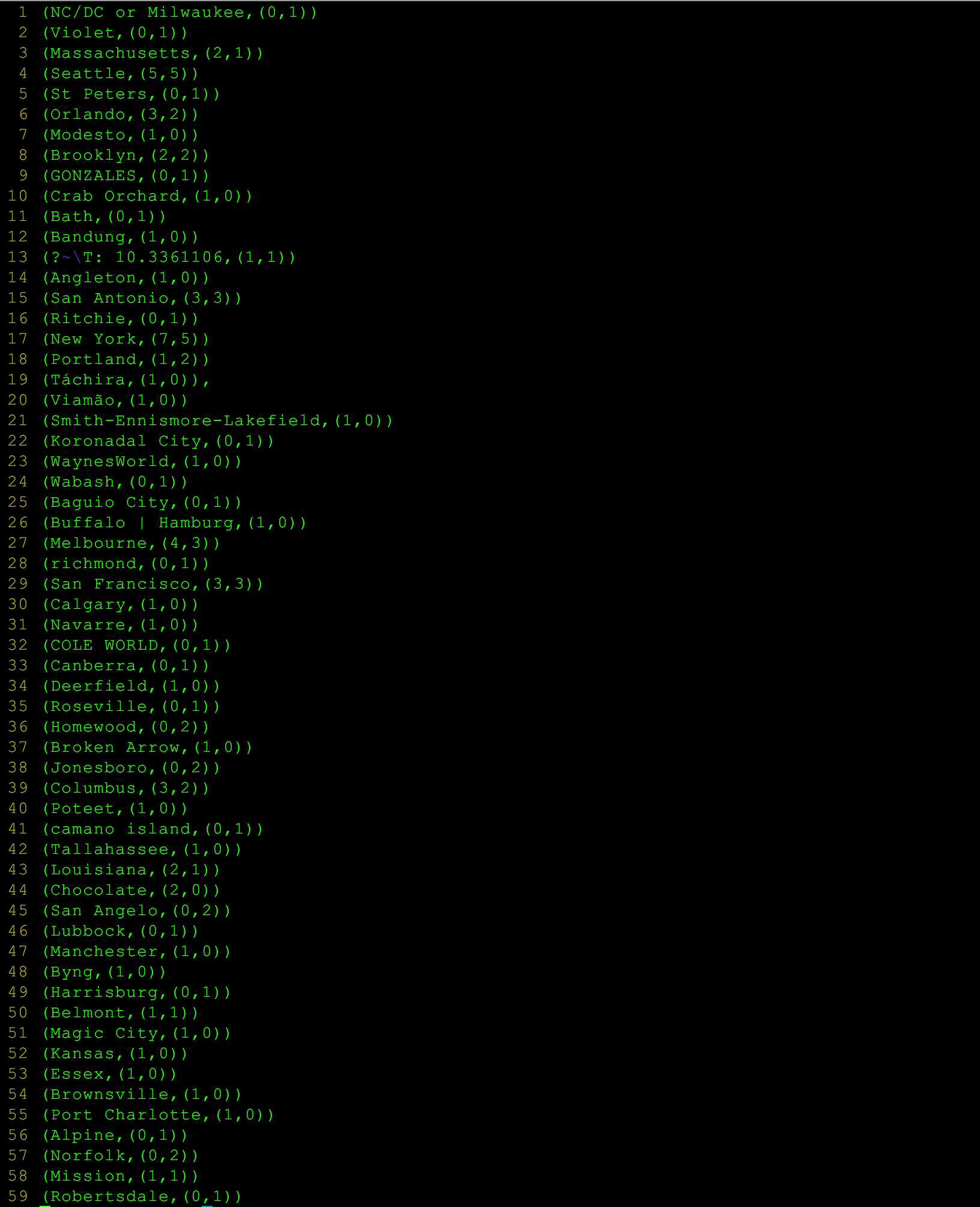
Results
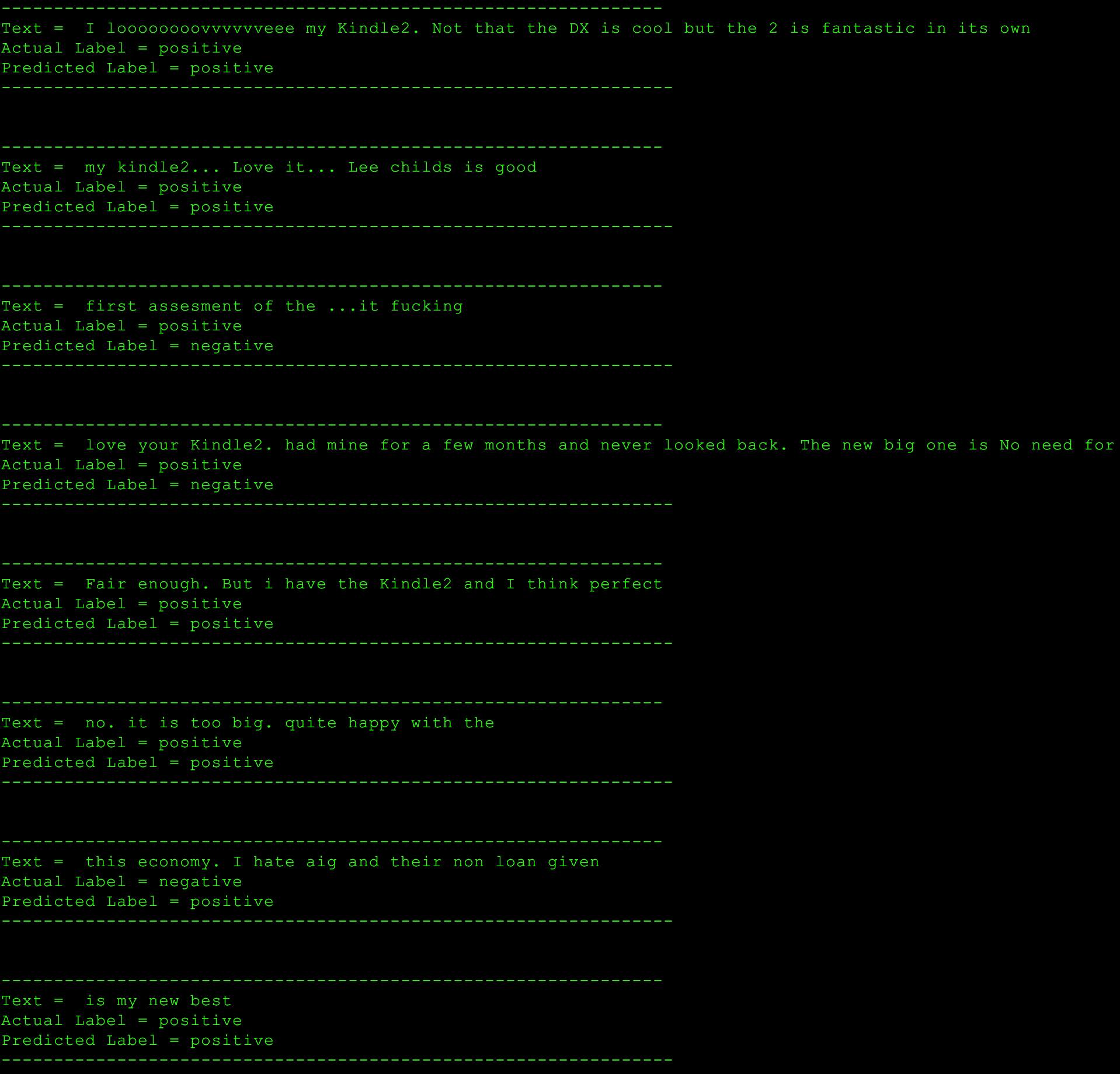
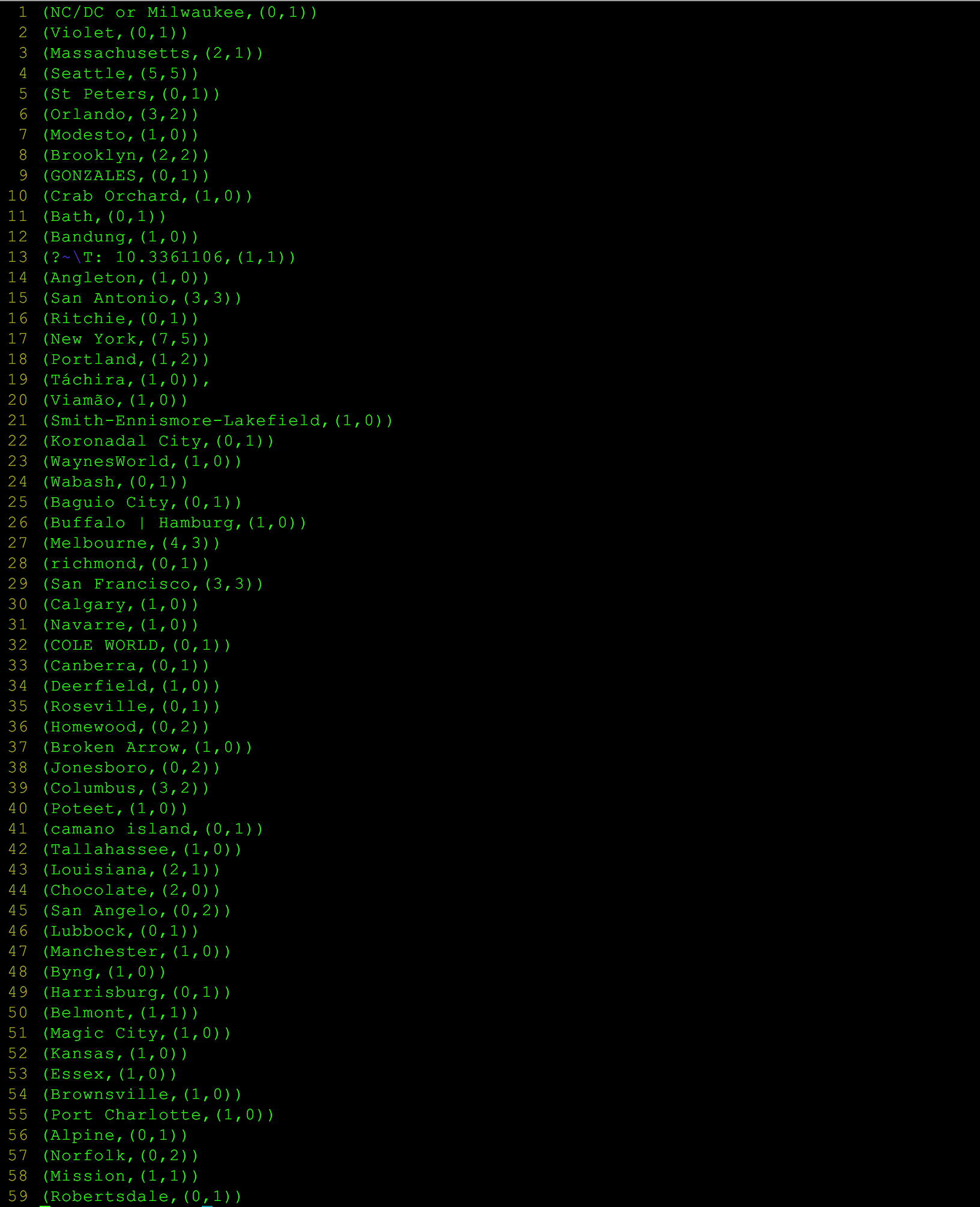
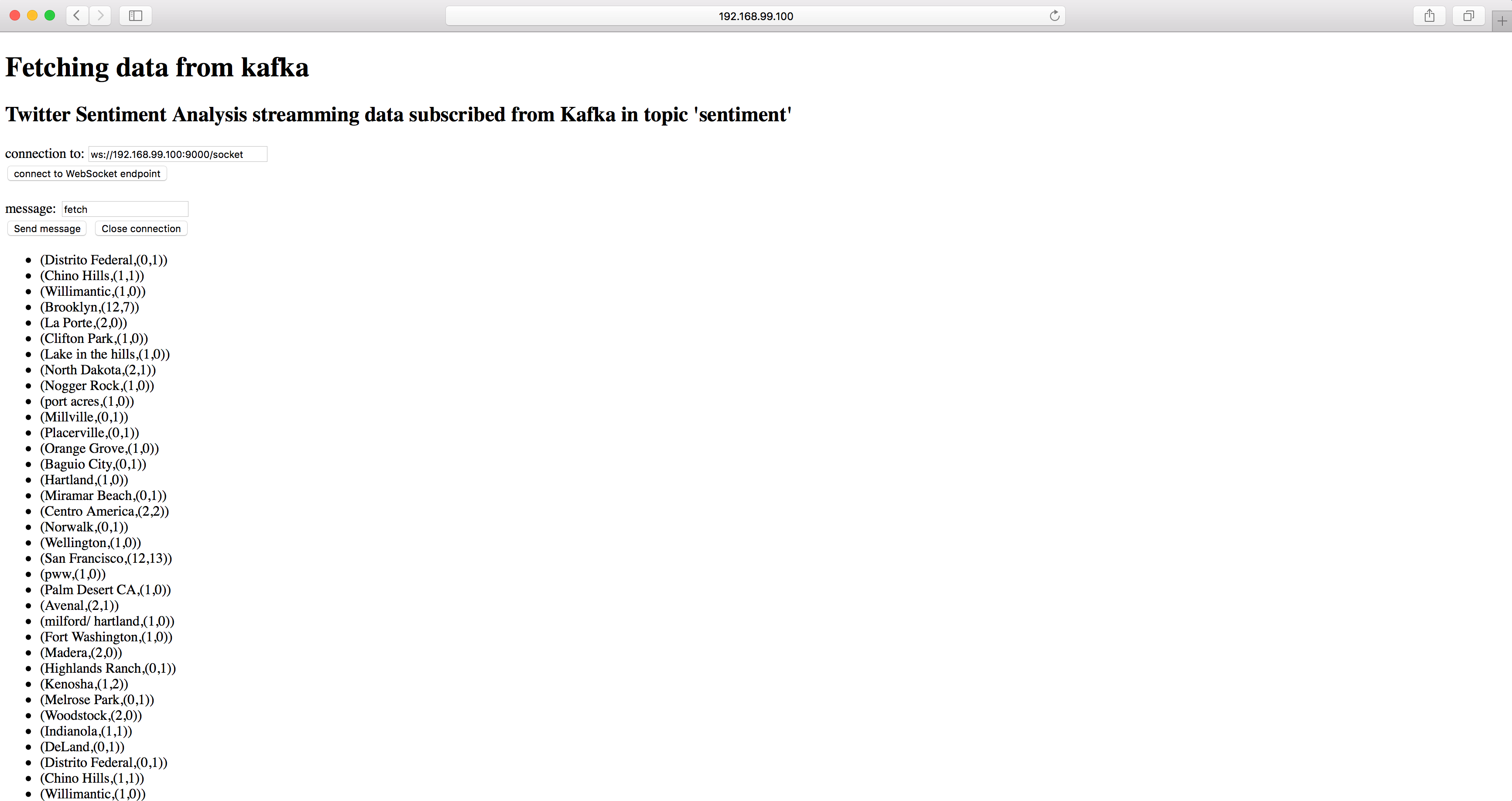
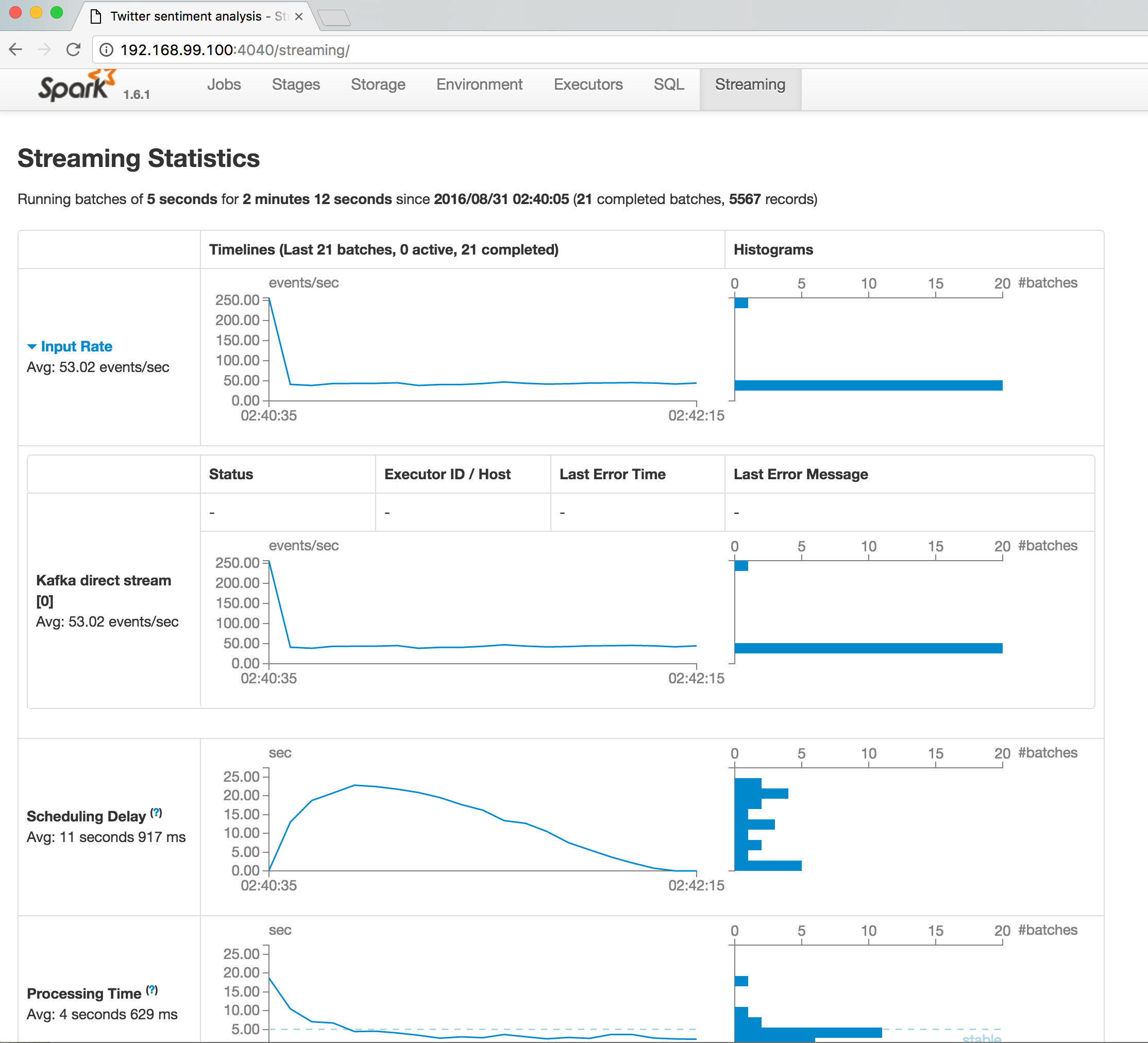
Wrap up
This is a really fun and valuable project that I have learned distributed system, like Apache Kafka and Apache Spark(both have partitioned data to achieve data distribution and parallelism), machine learning algorithm, Naive Bayes Classifier, and Scala in functional programming. When I review this project, concurrent computing on JVM distributed system catch my attention because of Akka toolkit used by Apache Spark and Play framework, which emphasizes actor-model to achieve concurrency. Concurrent programming on JVM will be my next milestone.